
The development of AI models, particularly large language models (LLMs), consists of four stages: data preparation, pre-training, fine-tuning & alignment, and deployment & inference. Among these, data preparation is the most critical phase, accounting for 70–80% of the total development time and effort. While the emergence of transformer architectures has enabled self-supervised learning, technical (CAPTCHA, bot detection), legal, and policy (API restrictions, monetization) barriers continue to pose significant challenges in data acquisition.
The decline in data quality and reliability is another pressing issue in the AI industry. Data poisoning-in which adversaries deliberately introduce corrupted data-combined with the proliferation of AI-generated content degrade model performance and undermine trust in datasets. These challenges increase the risk of AI models producing inaccurate or biased results.
Grass addresses these challenges by establishing a decentralized web scraping network. Individual devices worldwide contribute their unused internet bandwidth as network nodes to retrieve and process web data, converting it into structured datasets optimized for AI training. Participants are rewarded with $GRASS tokens for their contributions.
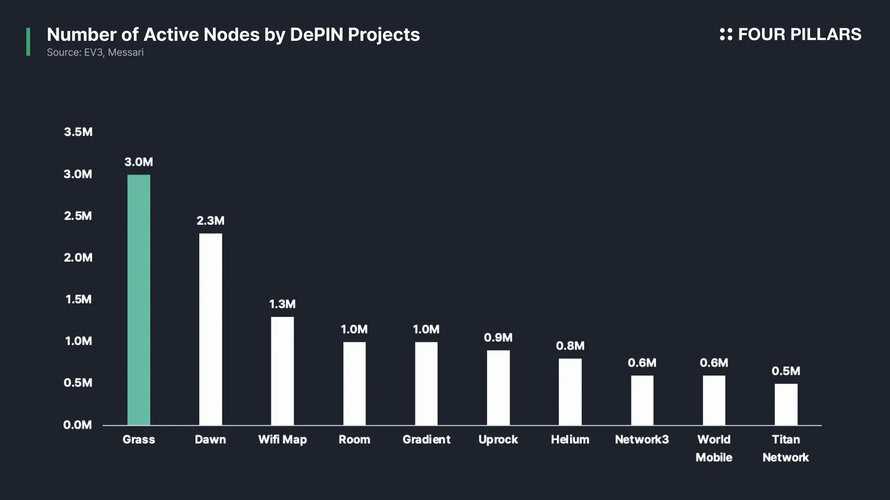
Grass has experienced remarkable growth. In 2024, its user base expanded 15-fold from 200,000 to 3 million, and it now operates with over 3 million nodes across 190 countries. As of March 5, 2025, the network recorded a cumulative 7-day web data scraping volume of 6,694 TB and has indexed 4.4 billion URLs since its launch.
Grass is now poised for further expansion with its Sion upgrade. By implementing distributed computing architectures, increasing processing speeds by 10x, and enabling large-scale multimodal data processing (including 4K video). These advancements strengthen Grass’s web scraping and crawling capabilities while opening new frontiers in AI data acquisition, positioning it as critical data infrastructure for the AI industry.
Introduction
Crypto fundamentally differs from traditional financial systems in that users can acquire assets not only through trading but also by directly contributing to networks and participating in their ecosystems. Unlike equity, which can only be acquired through purchase unless one is an insider, crypto assets are designed to enable users to engage in economic activities as network participants rather than mere consumers. This characteristic suggests that the crypto economy can transcend the category of investment assets to establish a new economic model centered on user participation—a feature that will likely trigger the natural influx of billions of ordinary users into the crypto economy.
From this perspective, DePIN (Decentralized Physical Infrastructure Network) emerges as the most noteworthy sector. DePIN protocols are defined by their ability to decentralize existing infrastructure such as transportation, energy, and wireless communications through blockchain’s core principles of transparent networks and verifiable reward systems. The appeal of DePIN lies in its dual capacity to demonstrate blockchain’s practical value by addressing real-world infrastructure challenges while simultaneously encouraging voluntary participation from general users who have previously shown little interest in the crypto market. Notably, DePIN’s tokenomics model, which combines blockchain advantages while resolving traditional industry inefficiencies, holds the potential for exponential growth through network effects.
Recent political shifts are likely to favor the growth of the DePIN sector. The anticipated regulatory easing under the Trump administration is expected to accelerate U.S. market entry for DePIN protocols that have been constrained by stringent policies such as Chokepoint 2.0.
Today, the total market cap of the DePIN sector stands at approximately $20 billion, representing an extremely early-stage market that accounts for less than 0.01% of traditional infrastructure industries. While over 13 million devices currently participate in DePIN networks daily, one protocol in particular has demonstrated particularly remarkable growth by securing 3 million nodes in a short period. This protocol is Grass Network, a decentralized network that provides AI developers with web data for model training.
Grass applies decentralized network principles to AI data acquisition, allowing individuals to contribute resources in exchange for rewards, similar to some DePIN models but focused on AI. By integrating blockchain-based incentive structures with distributed web data collection, Grass is reshaping how AI models access and utilize information, ensuring a scalable and verifiable data supply for the AI industry.
Challenges AI Companies Face in the Data Training Process
Before diving into a detailed analysis of GrassProtocol, it is essential to examine the core challenges facing the AI industry today. Grass Protocol has garnered significant attention precisely because it offers practical solutions to these fundamental issues.
As will be explored in detail in Section 3, Grass Protocol is a decentralized network that provides AI developers with web data for model training. This approach aims to address the structural challenges that arise during the dataset collection phase, the first and most critical stage of the AI development pipeline, by leveraging blockchain technology. AI companies today face two primary obstacles in securing web data: centralization and monopolization of data, and deterioration of data quality. These issues not only hinder individual enterprises but also act as systemic barriers that impede the overall advancement of the AI industry.
Data Centralization and Monopolization
AI development, particularly LLM development, consists of four stages: 1) Data Preparation, 2) Pre-training, 3) Fine-tuning & Alignment, and 4) Deployment & Inference.
Among these, the data preparation phase is the most decisive in determining the overall quality of the training process. It also represents the most resource-intensive stage, consuming an estimated 70–80% of the total time and effort required for AI development. The primary objective at this stage is to curate and refine high-quality datasets, transforming them into a format suitable for model training. This process involves three key steps: 1) web crawling and scraping for data collection, 2) data cleansing and filtering, and 3) text tokenization. The quality of the input data directly influences model performance—flawed data can lead to unreliable outputs and even ethical concerns, reinforcing the principle of “Garbage in, garbage out.”
The pre-training phase involves training general-purpose LLMs on massive datasets to develop foundational language capabilities. This stage employs self-supervised learning techniques based on transformer architectures, enabling the model to autonomously grasp linguistic patterns and contextual relationships. Given that this process requires trillions of tokens and immense computational resources, it represents the most capital-intensive aspect of AI model development.
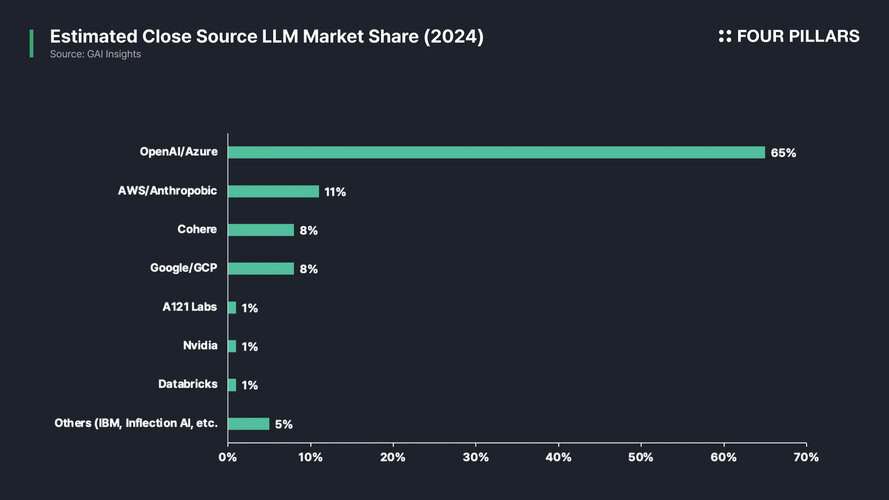
In this context, the volume and quality of data serve as key determinants of competitiveness in LLM development. It is no coincidence that big tech companies such as Microsoft and Google—both of which control search engines and vast troves of user data—have established a dominant position in AI. Through exclusive data partnerships, proprietary patents, internal user data utilization, and industrial-scale web scraping infrastructure, these corporations have secured privileged access to the highest-quality datasets.
The introduction of transformer-based architectures has enabled self-supervised learning without the need for manually labeled data, yet significant obstacles remain in web data scraping. This is particularly critical for acquiring real-time data. While static knowledge, such as mathematical computations or basic factual relationships, can be adequately learned from structured encyclopedia-style datasets, real-time data is indispensable for understanding public sentiment on specific topics or rapidly evolving social trends. Given that billions of users constantly share their thoughts and opinions on social media, these platforms have emerged as a crucial data source for addressing contemporary AI challenges.
However, website operators have implemented a range of technical, legal, and policy-based measures to restrict AI companies from indiscriminately collecting data:
- Technical restrictions: CAPTCHA and bot detection systems, request rate limiting, authentication requirements, data obfuscation and non-standard HTML structures, API access limitations and monetization.
- Legal and Commercial Restrictions: Many websites explicitly prohibit automated data collection through their Terms of Service (TOS) and robots.txt policies, barring AI firms from scraping or crawling their content. Additionally, some platforms have pursued litigation to enforce these restrictions, as seen in cases like LinkedIn vs. HiQ Labs (2017–2022), where U.S. courts ruled that scraping publicly accessible data does not violate the Computer Fraud and Abuse Act (CFAA)—though legal debates on AI data collection remain unresolved. AI firms have countered these restrictions by citing fair use and implementing anonymization techniques to comply with privacy regulations such as GDPR and CCPA.
- Policy changes: Discontinuation of free API access by platforms such as Reddit, X (formerly Twitter), and Meta; licensing requirements imposed by news outlets such as The New York Times for AI companies seeking to use their articles.
These developments are accelerating the shift toward a “walled garden” internet model, where access to valuable data is increasingly restricted. In response, AI firms have employed various technical workarounds, including headless browsers (e.g., Puppeteer, Playwright, Selenium), CAPTCHA bypass techniques, and API reverse engineering. Large corporations further leverage their formidable legal teams to maintain an edge in data acquisition, partnership negotiations, and intellectual property rights.
A notable case in this landscape is the Chinese AI firm DeepSeek, which, despite facing greater constraints on data accessibility compared to OpenAI, has managed to establish itself as a formidable competitor. DeepSeek’s success can be attributed to four key strategies: 1) leveraging domestic web platforms such as WeChat, Weibo, Zhihu, and Bilibili—sources largely inaccessible to OpenAI—for news, research papers, corporate data, and social media insights, 2) maximizing the use of open-source and public datasets, including Common Crawl, Wikipedia, ArXiv, and GitHub, 3) optimizing model architectures through novel transformer structures such as Mixture of Experts (MoE) and Retrieval-Augmented Generation (RAG), and 4) securing robust backing from the Chinese government.

However, DeepSeek’s case remains difficult to generalize. The company has benefited from a unique set of conditions, including state support and privileged access to domestic datasets from major firms such as Baidu, Tencent, and Alibaba. As such, its model does not offer a scalable or universal solution to the broader issue of data monopolization in the global AI ecosystem. Ultimately, data accessibility remains a critical challenge in AI development and continues to drive industry centralization.
Data Quality and the Growing Need for Provenance
Another critical challenge facing the AI industry is the decline in data quality and growing need for provenance in datasets. Since data is the most crucial factor determining an AI model’s performance, the presence of manipulated or distorted datasets poses a significant risk, leading to inaccurate or biased outputs. The primary causes of declining data quality can be broadly categorized into two key issues: data poisoning and the proliferation of AI-generated content.
Data poisoning is a technique in which adversarial actors deliberately introduce incorrect or corrupted data into training datasets to degrade AI model performance. This tactic is used both as an offensive strategy (adversarial attacks) aimed at disrupting specific models and as a defensive measure (anti-scraping strategies) employed by websites seeking to hinder AI companies’ web data scraping efforts. As AI firms increasingly rely on web crawling and scraping to collect data, some websites have begun deploying data poisoning techniques to render scraped data unusable or to inject misleading information.
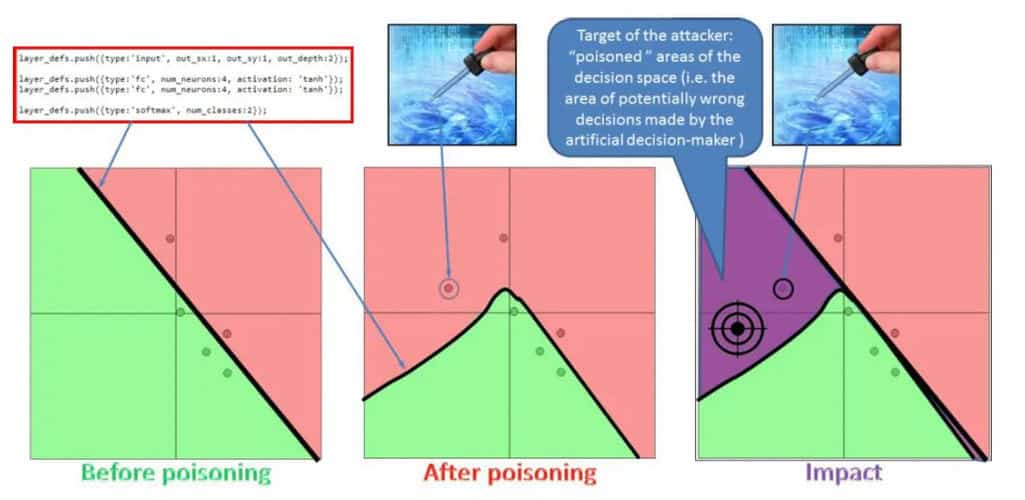
Data poisoning takes multiple forms. Some online forums and websites deliberately insert misleading information to confuse AI models. Tools like Nightshade allow artists to embed imperceptible distortions into their images, subtly altering pixel data in a way that remains undetectable to human viewers but disrupts AI learning processes. By corrupting training data, these methods serve as a defense against unauthorized data scraping.
Additionally, websites employ various technical countermeasures, such as dynamically modifying HTML structures, converting text into images, and implementing anti-crawling mechanisms. Major platforms like X, Facebook, and Instagram frequently obfuscate their HTML elements to prevent AI crawlers from extracting content.
A more direct form of data poisoning involves inserting glitch data into websites—data that remains comprehensible to human readers but introduces distortions that disrupt AI training. This includes subtle spelling modifications, artificial synonym replacements, or hidden watermark patterns embedded in text, allowing website operators to detect whether AI models have used their data. Some entities have even deployed honeypot pages containing deliberately fabricated information, which AI companies inadvertently scrape, only to later face legal repercussions.
Data poisoning not only degrades AI model performance but also undermines the long-term credibility of the entire AI ecosystem. If models are trained on misleading information, the consequences can be severe, leading to erroneous legal interpretations, historical inaccuracies, and the spread of misinformation. For example, if a malicious actor injects distorted historical data into training sets, an AI model could inadvertently propagate false narratives. This poses serious risks in critical industries such as law, healthcare, and finance, where precision and accuracy are paramount.
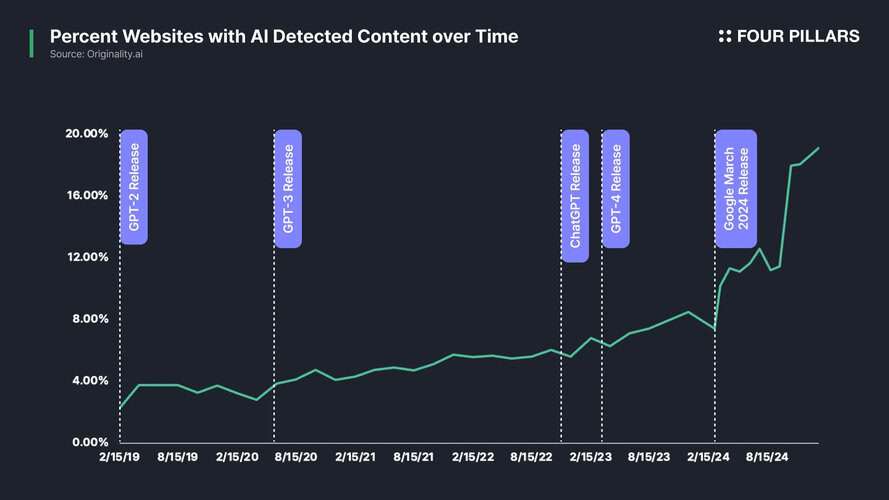
At the same time, the rapid proliferation of AI-generated content has emerged as another major driver of declining data quality. According to a study by AWS researchers, 57% of all content currently published online is either generated by AI or translated using AI algorithms. As AI models continue to generate an increasing share of digital text, images, and videos, they are increasingly learning from “AI-created data” rather than original human-generated content. This phenomenon, known as data inbreeding, leads to models that recursively train on their own synthetic outputs, resulting in progressive degradation of their generalization capabilities.
Since the launch of ChatGPT, the volume of AI-generated media has surged, further exacerbating this issue. Europol forecasts that by 2026, AI will be responsible for producing 90% of all internet content. The inclusion of AI-generated data in training datasets risks reducing data diversity, thereby impairing the model’s ability to adapt to real-world changes. In turn, this weakens AI models’ contextual awareness, increases the likelihood of generating inaccurate predictions, and amplifies inherent biases in the training data.
Grass Overview
The fundamental objective of blockchain technology is to establish a transparent, verifiable network where incentive mechanisms encourage diverse participants to contribute to platform operations. Grass leverages these strengths to create a decentralized network specializing in web scraping, real-time context retrieval, and web data collection for AI companies. Within the Grass Network , individual devices worldwide function as nodes that gather and process raw web data, transforming it into structured datasets optimized for AI training. In return, users who contribute resources to this process receive appropriate incentives.
This high level of accessibility has served as a powerful driver of mainstream adoption, attracting not only crypto-native users but also a broad base of general users. In 2024 alone, the platform’s user base grew 15-fold from 200,000 to 3 million, while the number of indexed videos surged nearly 1,000-fold. Additionally, over 2.2 million users received an airdrop distribution totaling $196 million at the time. The network now boasts more than 3 million nodes, with users from 190 countries participating in data provision.
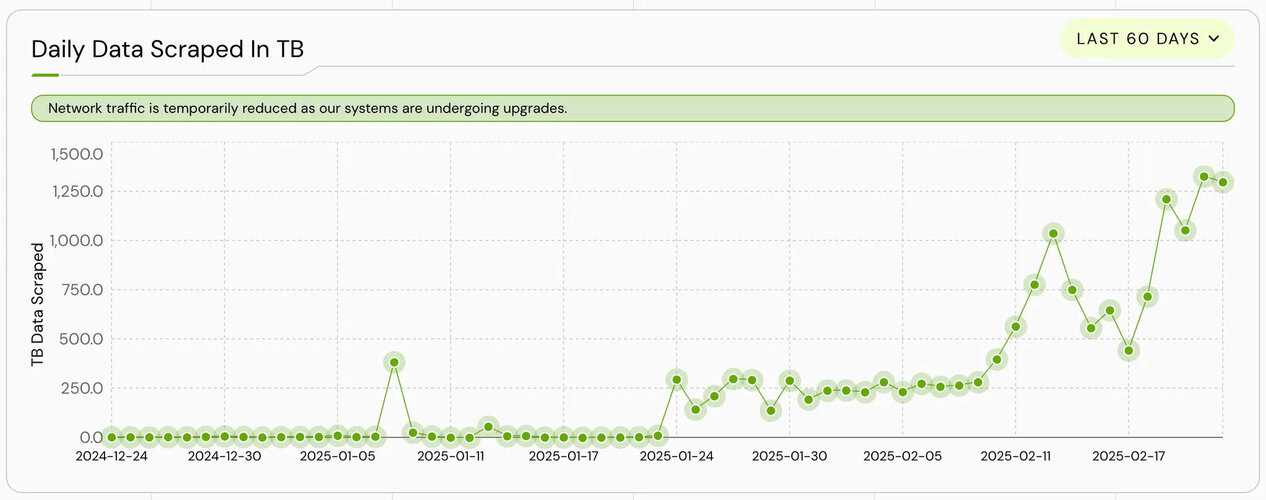
According to the Grass Foundation, the network has demonstrated substantial data processing capabilities, recording a seven-day cumulative scraping volume of 6,694 terabytes (TB) as of March 5, 2025. This figure has shown significant recent growth, likely attributed to the increasing impact of the ongoing Sion upgrade. Since its launch, the network has successfully indexed approximately 4.4 billion URL, highlighting its extensive reach in web data collection.
What Gives Grass Its Competitive Edge?
Grass has achieved remarkable growth in a short period by effectively addressing the needs of both data suppliers (node operators or users) and data consumers (AI companies). On one side, individual users are incentivized with rewards in exchange for contributing their unused internet. On the other, AI companies gain direct access to high-quality public web data—collected through Grass’s decentralized scraping network and pre-processed into ready-to-use datasets. This competitive advantage can be analyzed from two key perspectives.
Leveraging Residential IPs for Efficient Data Collection
IP addresses used for web scraping fall into two categories: datacenter IPs and residential IPs. Datacenter IPs are frequently associated with automated scraping activities and are often blocked by websites. In today’s AI market, many major web platforms—particularly those in partnerships with centralized AI firms—actively employ datacenter IP bans and data poisoning strategies to restrict competitors’ access to valuable data.
By contrast, residential IPs are perceived as regular user traffic, making them far less susceptible to access restrictions. Grass’s decentralized network architecture allows it to leverage residential IPs from individual users, effectively bypassing technical barriers such as IP blocking, CAPTCHA verification, and access limitations that traditional centralized data providers encounter.
Importantly, Grass maintains a strong focus on user privacy protection. The network does not collect personal information through its nodes; instead, IP addresses for routing purposes. This helps to ensure that all other personal information of Grass users is not disclosed and remains confidential.
Ensuring Data Provenance with Blockchain and ZK Processors
One major challenge in the AI industry is verifying the provenance of training data. As discussed in Section 2.2, the rise of AI-generated content and deepfakes has blurred the line between accurate and misleading information. In this environment, ensuring the credibility and verifiable origin of datasets used for AI training is becoming increasingly critical. Grass aims to address this issue through blockchain technology.
In the future, every time a Grass node scrapes data, metadata verifying its source is recorded on the blockchain. This metadata will be permanently embedded in all datasets, allowing AI developers to trace the origin of the data they use. Developers will then be able to share this verified data history with their end-users, reinforcing trust in AI models by ensuring they are not trained on intentionally misleading information.
Maintaining this level of metadata verification will require a higher transaction throughput than most general purpose L1 blockchains can offer. To address this challenge, Grass is exploring a Sovereign Rollup to batch-verify metadata. Specifically, Grass’s Sovereign Rollup will utilize ZK processors to batch-verify metadata and provide a permanent, verifiable record for all datasets. Further technical details on this solution will be explored in Section 3.3.
Ultimately, Grass’s approach offers multiple advantages, from preventing data poisoning to supporting open-source AI development. More broadly, provenance-enabled data infrastructure is expected to play a pivotal role in enhancing the reliability and transparency of AI models.
Network Architecture
The Grass Network consists of two primary components:
- Grass Desktop App: An application that enables users to contribute their idle internet bandwidth to the network in exchange for $GRASS rewards.
Sovereign Rollup: A decentralized network composed of nodes, routers, validators, ZK processors, and a data ledger, responsible for sourcing and transforming unstructured web data into structured datasets. - A Sovereign Rollup is a blockchain that operates independently for transaction execution and settlement while relying on an external blockchain for data availability and consensus.
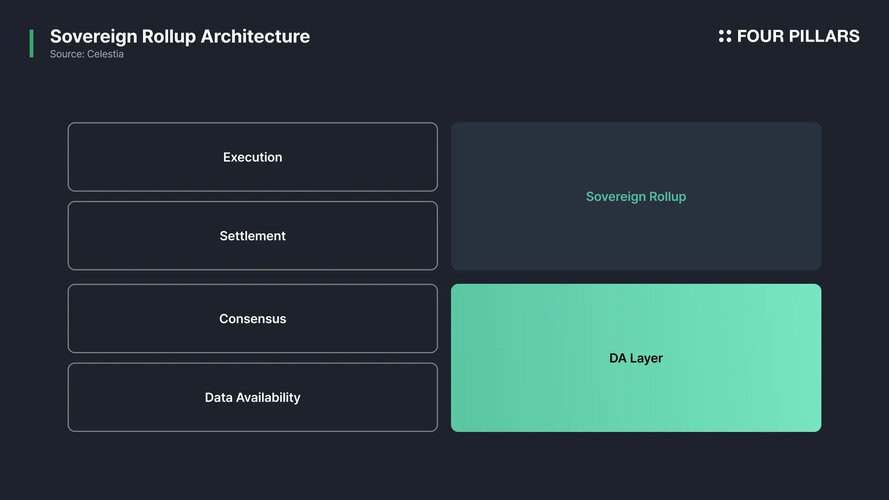
Grass will utilize Solana for consensus and data availability guarantees. However, transaction execution and settlement will be managed independently within Grass’s rollup. Notably, Solana will not verify the accuracy of Grass Rollup transactions—this responsibility will lie entirely with Grass’s validator nodes.
This architecture is designed to address the enormous data-processing demands of the network. Grass currently processes more than 200 terabytes of web data daily. If Grass were to rely entirely on an L1 blockchain for execution, competing for blockspace with other dApps, bottlenecks would emerge. Given that Solana already processes an average of 4,000–5,000 transactions per second (TPS), deploying a dedicated rollup is a logical and necessary decision.
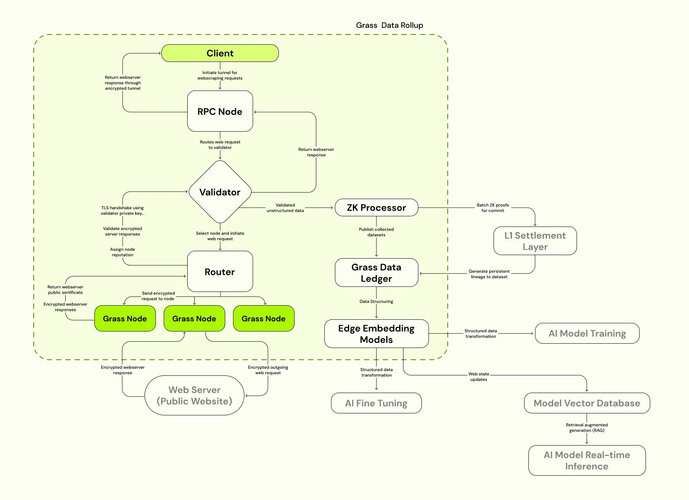
Transaction Flow and Key Components in the Rollup (Future Rollout)
Client Data Request
Transactions are initiated when a client submits a data request via an RPC node, which acts as an interface between the client and the Grass Network. Clients can include AI research labs, financial institutions, analytics firms, or the Grass Foundation itself acting on behalf of end users. Requests contain specific parameters, such as:
Target website or domain for data collection.
Time range (e.g., only content published after a certain date).
Filters such as keywords or content categories.
Validator Request Verification and Optimization
Validators analyze the feasibility of the data request and verify whether it complies with network requirements. Their key functions include:
Filtering redundant requests to optimize bandwidth usage.
Ensuring compliance with legal and network constraints.
Structuring requests for efficient parallel data collection.
Once verified, validators determine the optimal workload distribution among Grass nodes and relay this information to routers.
Router Task Distribution and Data Collection by Nodes
Routers assign scraping tasks to Grass nodes based on real-time factors such as node availability, geographic location, and bandwidth capacity to optimize network efficiency. Grass nodes execute the assigned tasks using residential IP addresses to retrieve data from the specified web sources. The collected data is encrypted and transmitted back to the router.
Validator Data Verification and Integrity Checks
Once data collection is complete, the scraped content is forwarded to validators for integrity verification. Validators perform critical integrity checks, including:
Ensuring collected data matches request parameters.
Verifying dataset completeness, consistency, and absence of data poisoning.
Recording source URLs, timestamps, and node identities for data provenance tracking.
This process is essential to ensure that AI models are trained on high-quality, verifiable data. Once verified, the dataset is passed to the ZK processor for cryptographic proof generation.
ZK Processor: Cryptographic Proof Generation and On-Chain Settlement
The ZK processor generates zero-knowledge proofs (ZKPs) to verify:
Dataset authenticity and provenance.
Grass node identity (while preserving user anonymity).
Exact data collection timestamps and sources.
Instead of storing entire datasets on-chain, cryptographic proofs batch-processed by the ZK processor are submitted to the Solana blockchain for permanent and immutable verification. The adoption of ZK processors is essential given that Grass is expected to handle millions of web requests per minute. Traditional L1 blockchains lack the capacity to process such volumes, making ZK-based verification and batch processing a critical scaling solution.
Grass Data Ledger: Storage and Accessibility
Once validation and cryptographic proof generation are complete, the structured dataset is stored in the Grass Data Ledger—the core storage layer of the network. This ledger functions as a bridge between off-chain data storage and on-chain proof verification, offering AI research firms and clients the following benefits:
Access to high-quality, integrity-verified datasets.
Full provenance tracking for training data, linking it back to its original web source.
Mitigation of data poisoning risks through immutability and verifiable origins.
Beyond processing individual web scraping requests, the ledger can also serve as a data repository strategically optimized for large-scale LLM training. This allows Grass to expand its business model beyond just real-time scraping.
Final Data Delivery to Clients
Once the data collection and verification process is complete, the final dataset is delivered to the client. Clients can access the dataset in two ways:
Directly through RPC calls to Grass Network.
Via API interfaces provided by the Grass Foundation, which acts as an intermediary data provider.
The final structured datasets can be applied across various industries and AI applications, including:
AI Model Training: Providing real-time, high-quality, and verifiable web data for model development.
Market Intelligence: Offering insights into financial trends, social sentiment, and geopolitical events.
Real-Time Decision Making: Integrating fresh web data into AI inference pipelines for up-to-the-minute analysis.
$GRASS Tokenomics
$GRASS serves three primary functions within the Grass Network.
First, it functions as a staking mechanism to enhance network security. Grass nodes and investors can stake $GRASS to routers, contributing to network security while earning rewards. In the future, routers will play a role in processing bandwidth traffic and reporting resource consumption per transaction. While slashing mechanisms are currently managed manually, plans are in place for an automated system as the network decentralizes. As of February 10, 2025, a total of 32.13 million $GRASS is staked, accounting for approximately 13.2% of the circulating supply.
Second, $GRASS will eventually serve as the payment method for network services, including web scraping operations, dataset purchases, and LCR usage. Currently, the Grass Foundation accepts payments in USD and USDC.
Third, $GRASS is used for governance participation, allowing token holders to vote on network improvement proposals, partnerships, and incentive structures, influencing the development trajectory of the Grass Network.
What’s Next? Scaling Multimodal Data Processing and Distribution
The AI industry is undergoing a paradigm shift as it moves beyond text-based models toward generative AI, autonomous systems, and robotics. The rise of multimodal AI has fundamentally altered the nature of data demand. The ability to process text, images, audio, and video in an integrated manner is now crucial for enhancing AI’s real-world perception and operational accuracy. As real-world applications—ranging from self-driving vehicles interpreting road conditions to AI-powered robots manipulating objects—continue to grow, the demand for high-quality multimodal datasets has intensified.
However, the AI industry currently faces a data supply bottleneck. Existing data sourcing methods suffer from three fundamental limitations:
- Soaring data acquisition and processing costs.
- Fragmented data formats and structures, making seamless integration challenging.
- Limited scalability in handling petabyte-scale datasets.
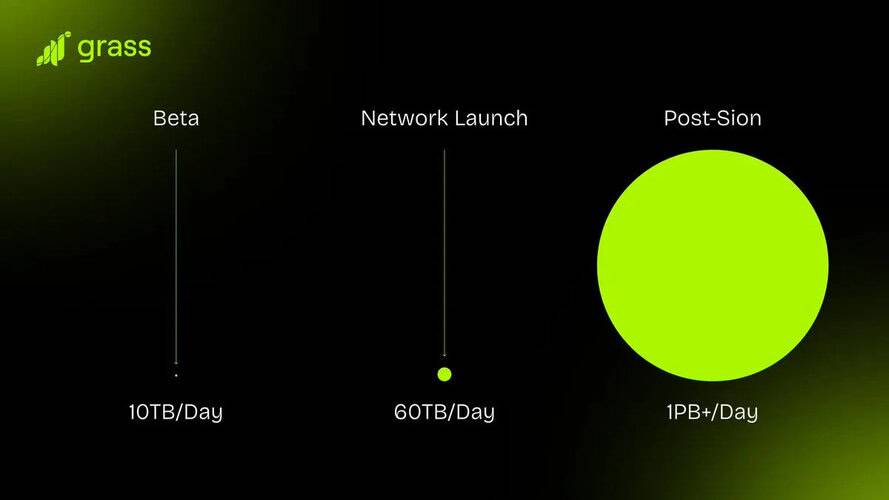
These constraints are now becoming major roadblocks to the next generation of AI development. To address these challenges, Grass has announced a major infrastructure upgrade known as Sion. The core objective of Sion is to significantly enhance multimodal data processing capabilities—including support for complex, high-bandwidth tasks such as real-time 4K video processing. Sion follows a phased approach to ensure a stable expansion of the network’s capabilities.
Phase 1 (Completed): Focused on algorithmic optimizations. By refining the software architecture, Grass improved processing efficiency without requiring additional hardware upgrades. Any system limitations identified during this phase were incorporated into the design of Phase 2.
Phase 2 (Current): Focused on physical infrastructure expansion. Grass plans to implement distributed computing architectures to efficiently distribute workloads and increase network bandwidth capacity beyond 1 terabit per second (Tbps), improving data processing speeds by over 10x. One of the most notable advancements in Phase 2 is the adoption of adaptive scraping, enabling seamless collection and processing of 4K video, images, text, and other multimodal data formats.
With the successful execution of the Sion upgrade, Grass is poised to evolve beyond traditional scraping and establish itself as a leading provider of high-quality multimodal data for the AI industry.
Looking Ahead
Grass stands out as a practical solution to the AI industry’s growing data supply challenges. What makes its approach particularly compelling is that it is not merely a technological experiment but one that is fundamentally aligned with real market demand.
The demand for AI training data continues to rise, and with it, Grass’s role is likely to become increasingly significant. Growth in data demand translates directly into higher revenue for Grass, which in turn fuels network expansion, increased node participation, faster and larger-scale data collection, and the development of more competitive datasets. Two upcoming launches could accelerate this growth trajectory: the mobile launch, which has the potential to increase the number of nodes and enhance network effects, and a hardware solution currently in its testing phase. If this flywheel effect takes hold, Grass will be able to consistently attract new customers and further solidify its position in the market.
Ultimately, the key challenge is scaling this flywheel efficiently. With an expanding network of contributors and AI companies seeking live, verifiable data, Grass is uniquely positioned to become the standard for decentralized AI data acquisition.







